Notes on LLM application development
Apr 13, 2024 - Portland
Like a lot of folks, I’ve integrated LLMs into my daily life, but until recently never had the time to dig deeper and form opinions about building with them.
In this post I’ll discuss the design of the chat facility in paintedtargets.com, followed by a discussion of moving between what I like to call the “structured data domain” and the “natural language domain.”
Painted Targets
For background, I enriched a biotech patent analysis website with a chat style interface allowing users to search, ask general questions, and ‘chat with patent applications’.
The site, which has prototype vibes, is up at paintedtargets.com.
A “Wrapper” Application
While the project uses local models on consumer GPUs for document classification, named entity recognition, and record linking, the main LLM component uses Google’s Gemini API.
I found that among the multitude of OSS LLM models available, none of them are going to run great on a 4090 or two, especially the larger SOA models. And you can forget about fine tuning the big ones. For now I am punting on the main LLM implementation as a detail behind an interface. I think this will be a popular choice even though it comes with the usual types of tradeoffs relating to cost, latency, throughput, and correctness.
A quick digression – ‘correctness’ is a bit of a dubious term when talking about LLMs, fitness for purpose, or even fitness to taste is perhaps more appropriate when discussing the correctness.
Opportunities for Wrapper Applications
The first question you have to ask yourself is why not just ask a big chat service directly?
-
While LLMs can remember and produce information they were trained on, their memory is a lossy compression encoded version of their training data. So remembering facts is a bit dicey, especially arcane facts with little or no representation in training data.
-
LLMs can effectively interpret language, but you know, sometimes it’s hard to put a request into language. You need to include sufficient information in the input to resolve an appropriate generation path. By adding some constraints to a problem, you reduce the size of the event space. This allows for building “tools” and prompts directed at a specific set of problems in which a lesser amount of information in the input and a lesser amount of information encoded in the model is sufficient for a successful computing experience.
The room to add value here will probably change over time.
Painted Targets Details
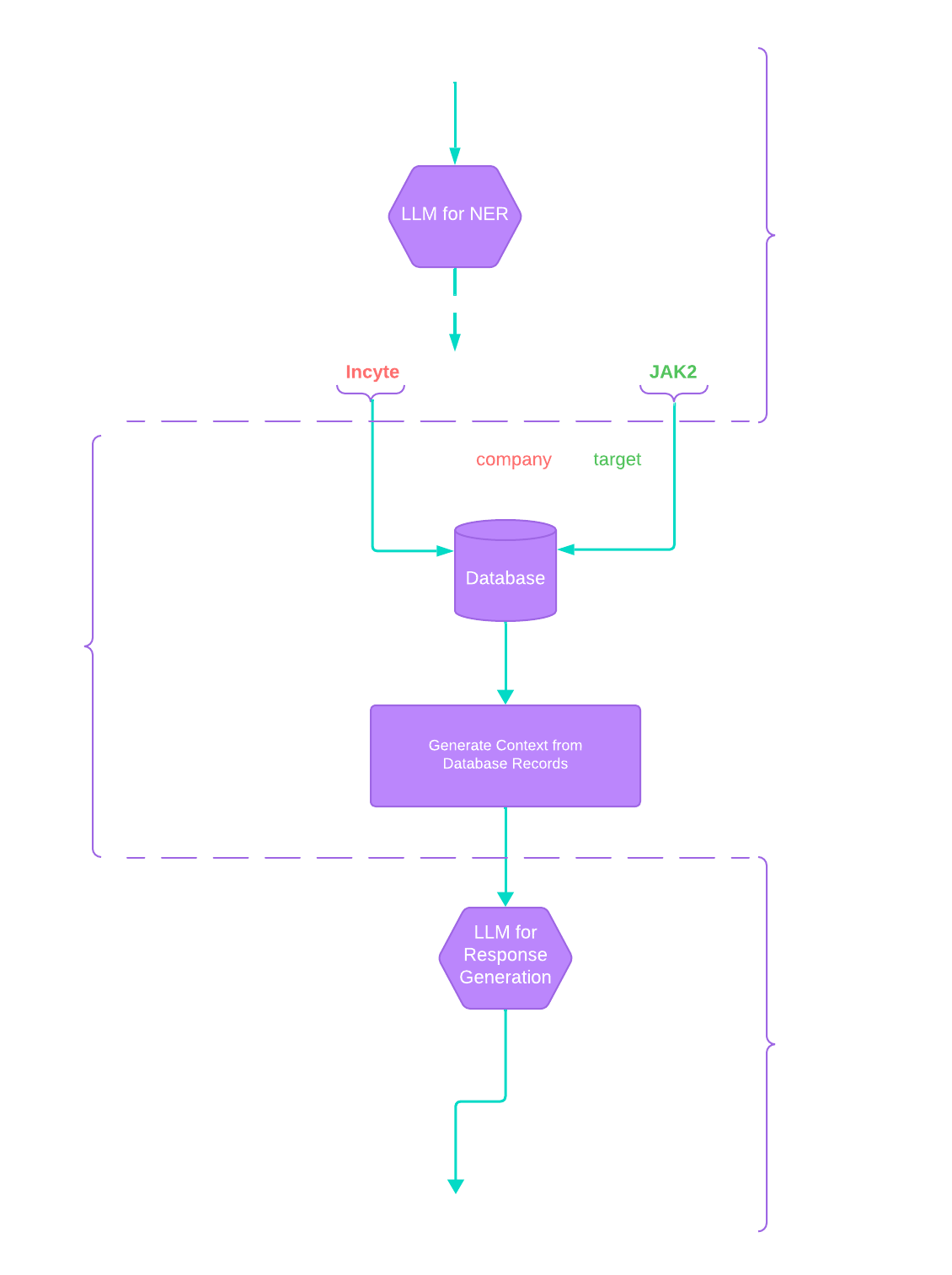
When a user submits a chat request to painted targets, it goes through a sequence of components to produce an answer.
A simplified high level diagram and discussion of components follows.

Let’s break down what each node in this graph does.
Classify Output
Here we classify the question by the type of output a user expects.
For paintedtargets this involves mapping any given question to one of the following categories.
- A list of patent applications
- A list of companies
- A list of drug targets
- A description of a relationship between two entities in the set of (companies, targets, diseases, pharmacology topics)
- General information about a topic
This is limiting. But it shrinks the problem space and helps us to build a context from structured data later.
Extract Entities
Here we identify what the user is asking about. Is the user asking about Incyte and JAK2? Or maybe their questions includes a reference to COVID-19 and ACE2.
It turns out that LLMs are pretty good at this task.
Combined with an expectation of the desired output we can use this as a bridge from the natural language domain to the structured data domain.
Quick digression here, for a long time, there has been a good pedantic point that natural language has structure. It was just the small matter of the information in natural language was sufficiently difficult to use that it was effectively unstructured for a broad range of computational uses. The information is more accessible now.
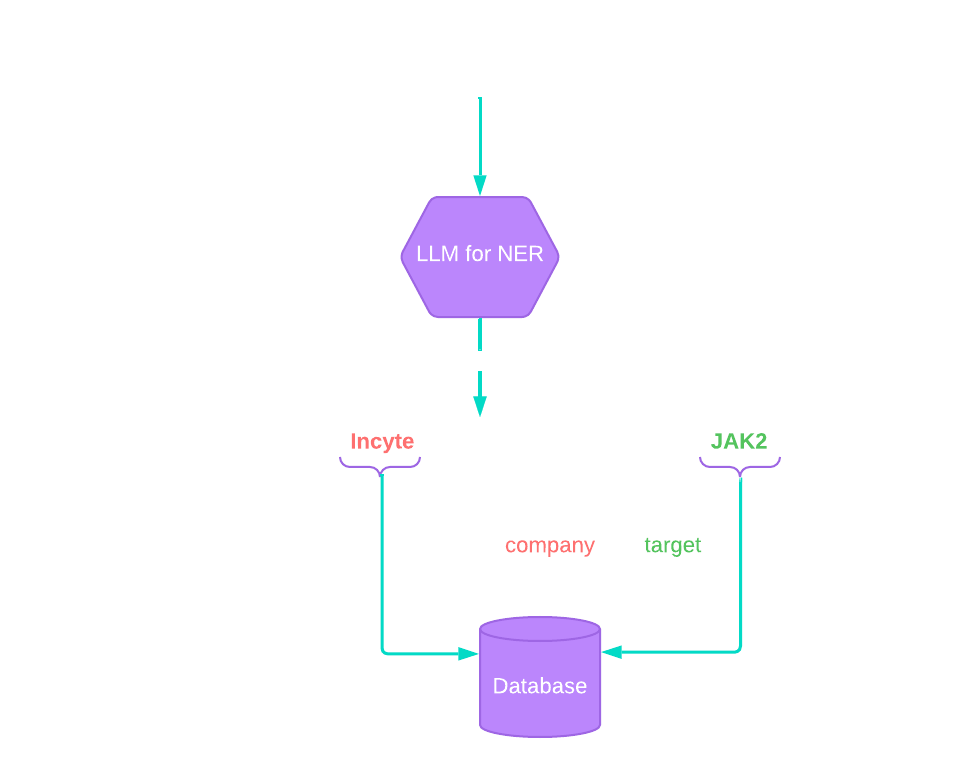
An essential aspect of this step is the transition from “unstructured” natural language to “structured” references to database records.
Generate Context
Given a type of expected output and a set of database records, it’s straightforward to extract structured data from a relational database.
For example, a list of patent applications request which includes entities of Pfizer and COVID-19 can retrieve patent applications from Pfizer referencing COVID-19. This is nothing more than a database query.
Text from patent application records and other data from the database is included in the context passed to the LLM.
Generate Answers
This is where a bit of the so called “prompt engineering” happens.
We submit the prepared context and the user’s question to the LLM and receive a response.
Consider the case where a user is asking a question about a specific patent. A simplified example of a generated prompt follows.
Please answer the following question using the provided context.
CONTEXT: Modulating The Immune Response Using Anti-cd30 Antibody-drug Conjugates
Provided herein are anti-CD30 antibody-drug conjugates and methods of using the
same to modulate the immune response in a subject. CD30 is a 120 kilodalton
membrane glycoprotein and a member of the TNF-receptor superfamily that has been
shown to be a marker of malignant cells in Hodgkin's lymphoma and anaplastic
large cell lymphoma (ALCL), a subset of non-Hodgkin's lymphoma. CD30 has been
found to be highly expressed on the cell surface of all Hodgkin's lymphomas
and the majority of ALCL ...
QUESTION: What drug conjugates are referenced in this application?
Generate Relevant Entities
For a subset of question types we may ask the LLM to make a relevance determination.
This uses a tool to extract structured records out of the context.
An interesting note is that this is where a large context allows some interesting tradeoffs. For example, if the user has a question about Novartis’s patenting activity for treating a given disease, we’ve seen how to access the relevant patent applications. But perhaps the user wants to further refine the query with a lot of nuance. It would be easy from an application development point of view to submit every patent Novartis has ever filed in the context and just let the LLM sort it out. Curating a context is expensive and comes with the risk of lost recall.
In this step the goal is to identify any entities that are particularly relevant from the context. This allows for presenting links or other detailed information from the database in the response.
Post-Processing
After receiving a response, we need to present it to the user.
In the case of painted targets may expect links. This step is essentially a presentation layer.
Let’s take a quick look at this in action.
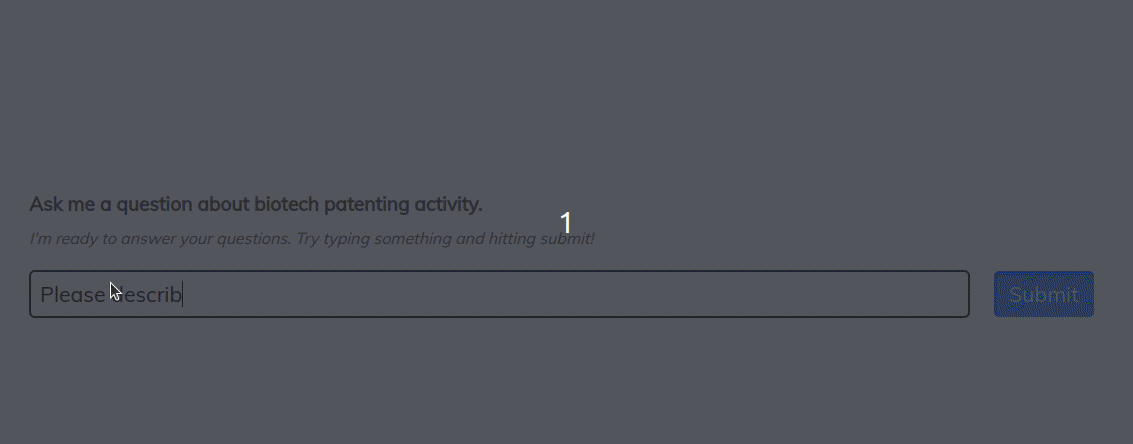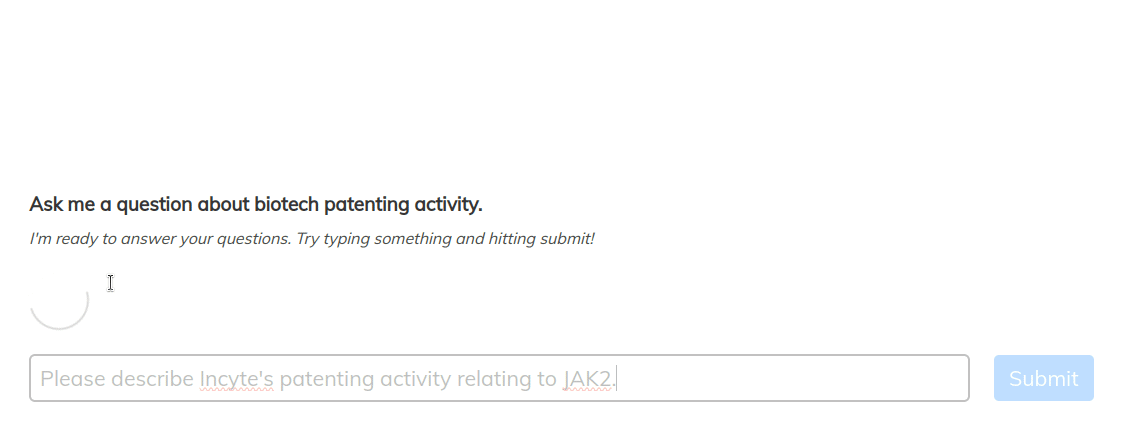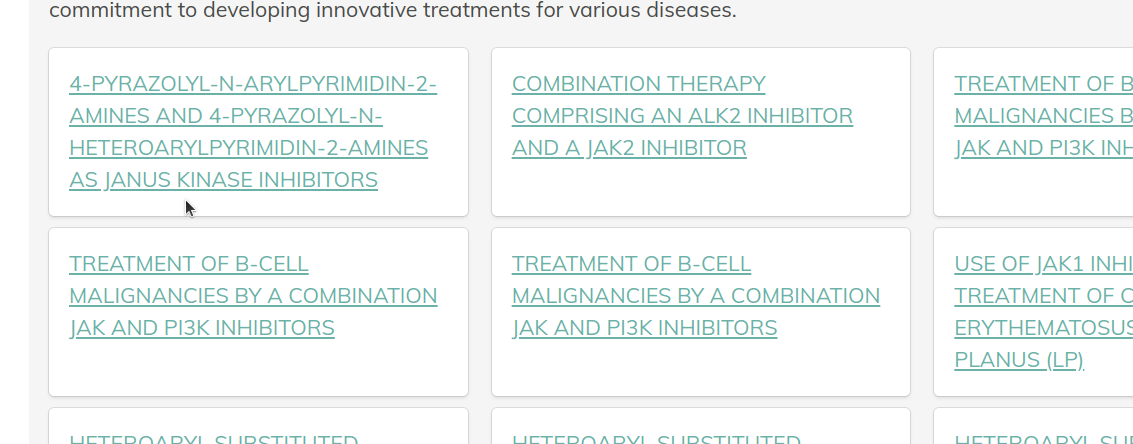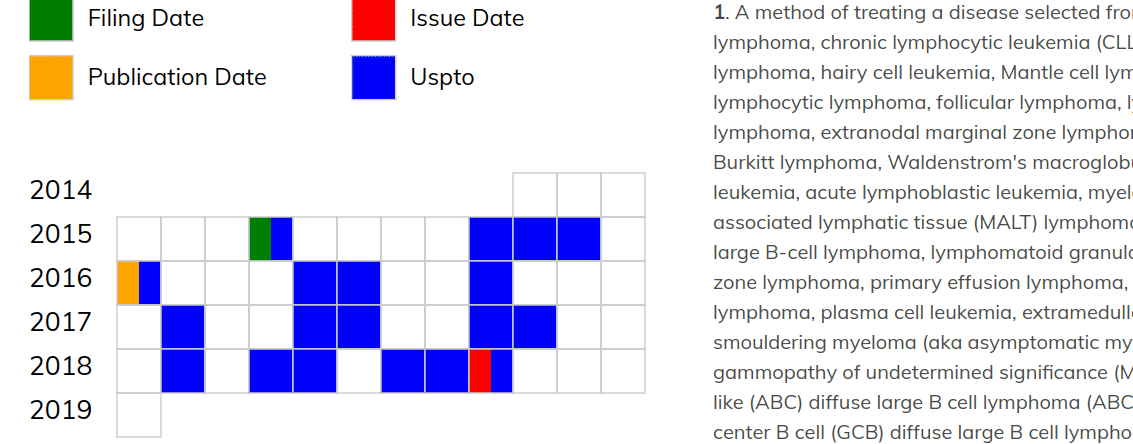
The Utility of Information Encoded in Language
Information is the reduction of uncertainty.
“What patent applications has Pfizer filed relating to GLP1?”
Consider a case in which we have 50,000 companies and 50,000 drug targets in our database and every question involves a combination of a company and a target.
Correctly identifying the pair a user is asking about is identifying 1 out of 2,500,000,000 combinations.
Now consider the set of possible phrasings the user could enter for any given pair.
In this case the transform from natural language to a set of database entities, the LLM acts a function that maps from the set all of reasonable input strings, bounded by validations on input length and chars, to the set of combinations of database entities and expected outputs.
Combining the known entities with the types of information the user is seeking, we will be able to compose appropriate database queries to generate a context for our reduced problem space.

Tools for implementing these functions have been around for a long time. Conditional Random Fields, Non-Transformer Networks, Regular Expressions, Various models for document classification etc.
But now entities can be extracted with zero shot or few shot prompting with decent results with a couple of minutes of effort. Same with document classification, relevance summarization, etc. This changes the economics of these projects, making many new applications possible.
The Utility of Information Encoded in Databases
LLMs can also curate an overwhelming amount of information.
This is the mechanism through which we can go the other direction. From an abundance of structured database records to a refined, direct, response in natural language.
Consider the following prompt template with the user’s question What are some interesting trends in Incyte's patenting activity for treating polythemia vera by targeting JAK2..
QUESTION: {normalized_question}
INSTRUCTION: Please use the following context to answer the question.
Do your best to create a description of the relationship based on following context.
Be creative and do your best.
CONTEXT: {context}
After extracting a disease, target, and company and an expected output as a general response, we query the database for patent applications with a restriction that is the intersection of these three keys. We then interpolate the contents of these patent applications for the context.
The LLM can then make information that was previously inaccessible, accessible.
Looking at the journey from natural language to structured data and back.
Something Terrible
There is something terrible about building an application like this.
You need to write code based on “business rules” tailored to the problem. All of which is very un-AI.
We do it to address the key limitations mentioned above: First, LLMs have a lossy representation of training data, imperfect recall, and a finite training data – further they can produce output detached from reality.
Second, there can be a mismatch between the information needed to select correctly the from the possible outputs and the information content of the input. A mismatch which can be shrunk by reducing the problem space and explicitly aligning with known entities and information structures in databases.
For now, there is real value in terms of accuracy and utility from journeying through the structured data domain.
Final thought
This mental model is really just Retrieval Augmented Generation but with a little more emphasis on named entity recognition, resolution, and database structure, as opposed to a shotgun vector similarity search.
We can imagine a lot of activity like this taking place with the concept of tool use. Where tools provide a in-LLM capabilities to access structured data sources.
And that reminds me of the old, healthy debate on the relative merits of managing complexity in Stored Procedures vs the Application Layer.
I’m willing to bet on the application layer.